
While writing my blog entry on Unicode Code, I mentioned the PETSCII encoding of the Commodore 64, which made me realise something odd: the Commodore 64 had basically two 7-bits text encodings. The shifted mode had lower-case letters, and the unshifted (default) one had graphical characters. Why not have one 8-bit encoding? As each character was represented by one byte in memory, why waste the upper bit?
Why this was designed this way I cannot say, but the upper bit was not wasted, as it marked a character qs inverted, this was used to implement the blinking cursor, blinking could be implemented by only turning a single bit in the graphical memory (which started at 0x400) on and off.
What I find fascinating is that in the history of computing, the representation of textual data has evolved quite a bit, these days, a text file can contain much richer and diverse forms of text. Yet this evolution has not been straightforward, with the trend basically oscillating between two ideas:
- A character is represented by a fixed numbers of k bits, and reading these bits gives you the character to display.
- The actual character you get for a given bit sequence depends on the previous bits in the text.
Of course what exactly constitutes a character is a complex question, whose answer changed with time.
A ſhort and inaccurate hiſtory of text encodings
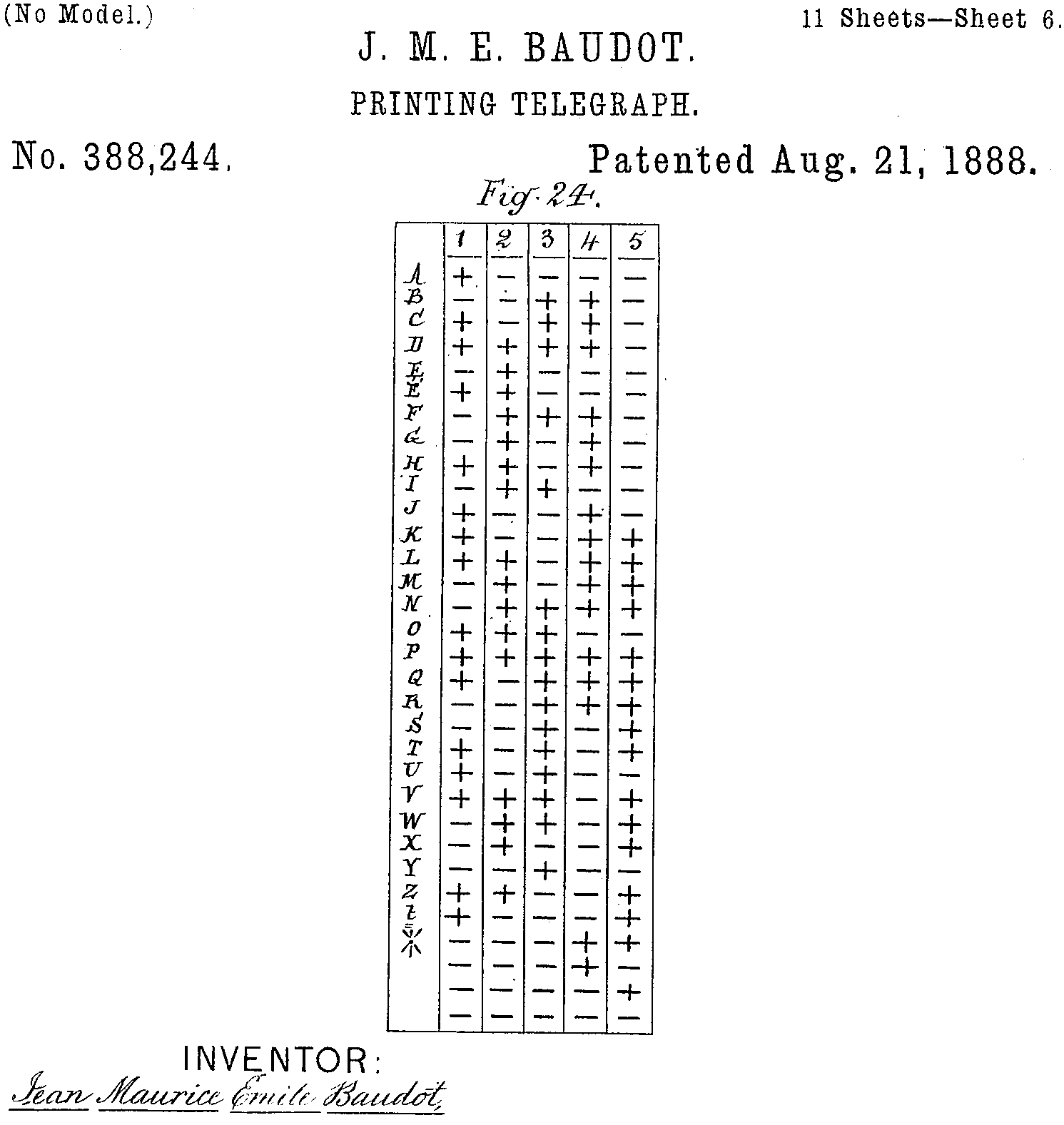
- Characters are represented as a 5 bit value (Baudot Code, 1874)
- Characters are represented as a 5 bit and the mode, which can be selected using special characters (Murray code, 1901).
- Characters are represented as a 7 bit value (ASCII, 1968)
- Characters are represented as a 7 or 8 bit value, and various modes which can be selected using special characters (ANSI escape codes, ~1970).
- Characters are represented as 16 bit value (UCS-2, ~1990)
- Characters are 16 bit values represented as a variable number of 8 bit characters
- Characters are 21 bit values represented as a variable number of 8 bit values
- Characters are 21 bit values represented as a variable number of 16 bit values
- Characters are a sequence of 21 bit values, each encoded as a variable number of 8 bit values
Modern text processing is typically a mishmash of all of the above since the appearance of ASCII. Which lead me to the question, how complicated can one character be nowadays? You can, of course, pile-up accents on a letter, but that is cheating. I wanted something someone from the US would recognise and say, yup, that’s a single thing, not some composite, and I recognise it. So I went for a big US flag, how many bytes can this be? The rule I set myself up is that this text appear fine in a terminal using just the cat command, and that each byte should do something, i.e. if you remove something, the text is changed.
So here are the 22 glorious bytes that display a big US flag in the Mac OS X terminal (with a line feed for clarity)1. So not only does every byte matter, but removing one might break 18 U.S. Code § 700, I don’t know, I’m not lawyer.
1B 23 33 F0 9F 87 BA F0 9F 87 B8 0A 1B 23 34 F0 9F 87 BA F0 9F 87 B8 0A
Let’s go over them. The first three bytes are all ASCII characters ␛#3 (escape-pound-three), and represent the DECDHL control sequence, which turns on the DEC Double-Height Letters, Top Half mode. The following 4 bytes represent one Unicode glyph in UTF-8, the Regional Indicator Symbol Letter U.
It is followed by 4 bytes that represent the Regional Indicator Symbol Letter S. Together these represent a US flag in Emoji. We then have another three ASCII characters, ␛#4 which this time is the DECDHL, i.e. DEC Double-Height Letters, Bottom Half, followed again by the sequence to get a US flag.
So here we have two unicode code-points used to represent a flag, each encoded as four bytes, once prefixed with a sequence that display the top half twice as big, and once prefixed with a sequence that displays the bottom twice as big.