
A few years ago, I read an internet an opinion piece I found interesting: Software systems and institutional xenophobia. It articulates clearly something that had me bothering for some time, that computer systems express a view of society that is pretty exclusive. One area where this is increasingly bothering me is language codes.
I could have written an article in the form, Falsehoods programmers believe about XXX, these get a lot of traffic, but in truth, programmers do not believe these things so much as translate some administrative beliefs into code.
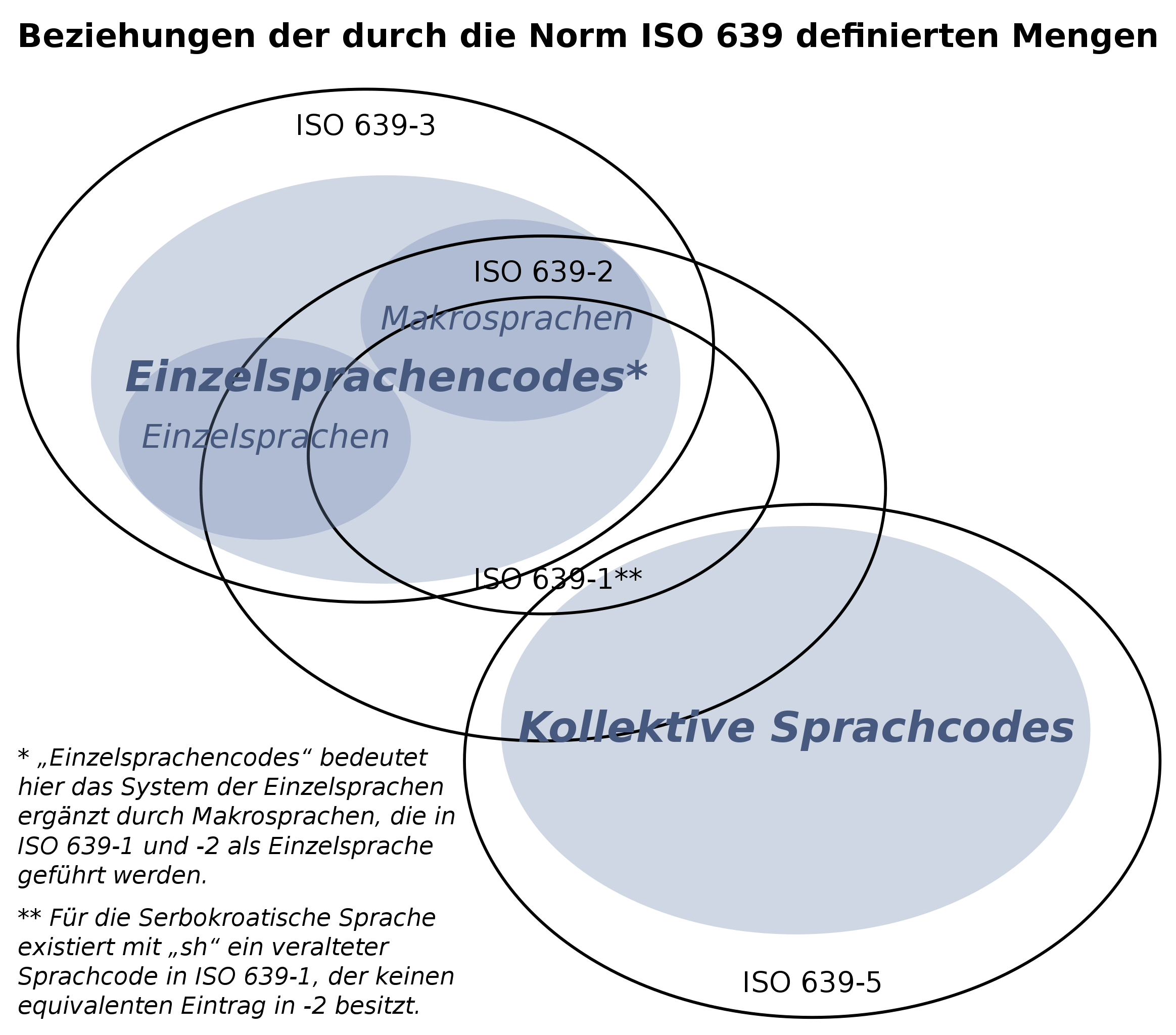
Language are generally described using RFC 5646, this is the official specification for web-pages and used by most major operating systems. A language is described by a tag, which starts with an ISO 639 language code (English for instance is en) followed by some variants tags. ISO 639 defines languages codes of differing lengths, the most common ones are two character long (ISO 639-1) but there is also a richer set which is three characters long (ISO 639-2). RFC 5646 allows the use of both, but when a two letter code is defined, that one should be used.
Some ISO 639-1 codes are macro-languages, a family of languages which are not mutually intelligible. Chinese (zh) is a typical example. At the same time, some mutually intelligible language like Serbian (sr) and Croatian (hr) are not defined with any kind of common ancestor. The artist language formerly known as Serbo-Croatian has an ISO 639-1 code (sh) but it is deprecated, it has an ISO 639-3 code (hbs).
Even if you consider language dialects, the relationship is not very clear, fr-CH is much closer to fr-FR than de-CH is from de-DE.
This is important because of language fallback, i.e. what to do when a resource is not available in given language. The classical solution is to fallback along the language tree. So what does RFC 5646 actually say on that matter?
The registry is therefore applicable to many applications that need
some form of language identification, with these limitations:It does not contain information about appropriate fallback choices when performing language negotiation. A good fallback language might be linguistically unrelated to the specified language. The fact that one language is often used as a fallback language for another is usually a result of outside factors, such as geography, history, or culture — factors that might not apply in all cases. For example, most people who use Breton (a Celtic language used in the Northwest of France) would probably prefer to be served French (a Romance language) if Breton isn’t available.
The schema shows the application domains of language codes, and well, the Venn diagram is pretty self explaining: the standards and the types of actual languages don’t overlap in any sensible way. So there is a language hierarchy, a nice tree model, but it is broken for the main use-case, language fallback, yet a lot of code uses it exactly for that…